
From Spaghetti to Simplicity
Rebuilding a Legacy Trading UI in a Global Bank.
Introduction
Over the past year, I was part of a very small team of senior engineers working to decommission an important legacy UI. It was used daily by traders to monitor options market volatility across the main regions: EMEA, NAM, and APAC. The project was far from easy. The UI was deeply embedded in the traders’ workflows, and the codebase had not seen a single commit since 2020.
Our team was intentionally small. We were all senior engineers, and the project demanded deep expertise rather than sheer numbers. It wasn’t about brute forcing lines of code, but about carefully navigating a fragile system, making sense of it, and eventually replacing it with something simpler, faster, and maintainable.
Why Not Just Fix the Old UI
Rewriting software often raises eyebrows. Isn’t it risky? Why not patch the existing system? In our case, the old UI was built on a tangled web of sagas, Redux, styled components, web workers, and React classes. Almost everything was a class, with complex lifecycles scattered everywhere. This was not limited to React classes; the entire UI followed a very strong object oriented programming design.
The client server contract relied on GraphQL, but the queries were enormous, filled with deeply nested fields and returning huge chunks of data. It simply was not the right tool for the job.
Even worse, none of us on the team felt confident making changes. Bugs piled up because attempts to fix one thing often broke something else. On paper, the project had excellent test coverage, but the tests themselves were weak. This was the textbook case where fewer but better tests would have gone much further. Coverage numbers gave a false sense of security without actually protecting the codebase.
The First Challenge: Untangling the Code
We spent weeks dissecting the old codebase, trying to understand the data flows and how the widgets were supposed to work. Those were the hardest weeks of the project for me.
Stakeholders pressed us for estimates and progress updates, but we were navigating a codebase nobody understood. Every original contributor had already left the company, so there was no one to ask. We knew it was a tough assignment; that’s why our team was chosen for it.
Our approach? Drawing. We sketched out every new discovery: how widgets connected, how data was fetched, and how it flowed across the app. These diagrams helped align our team on a common understanding and also helped the backend team redesign APIs in more meaningful ways.
Some diagrams were overwhelming. One widget alone could involve dozens of data lines and transformations.
This is the first one I personally drew.
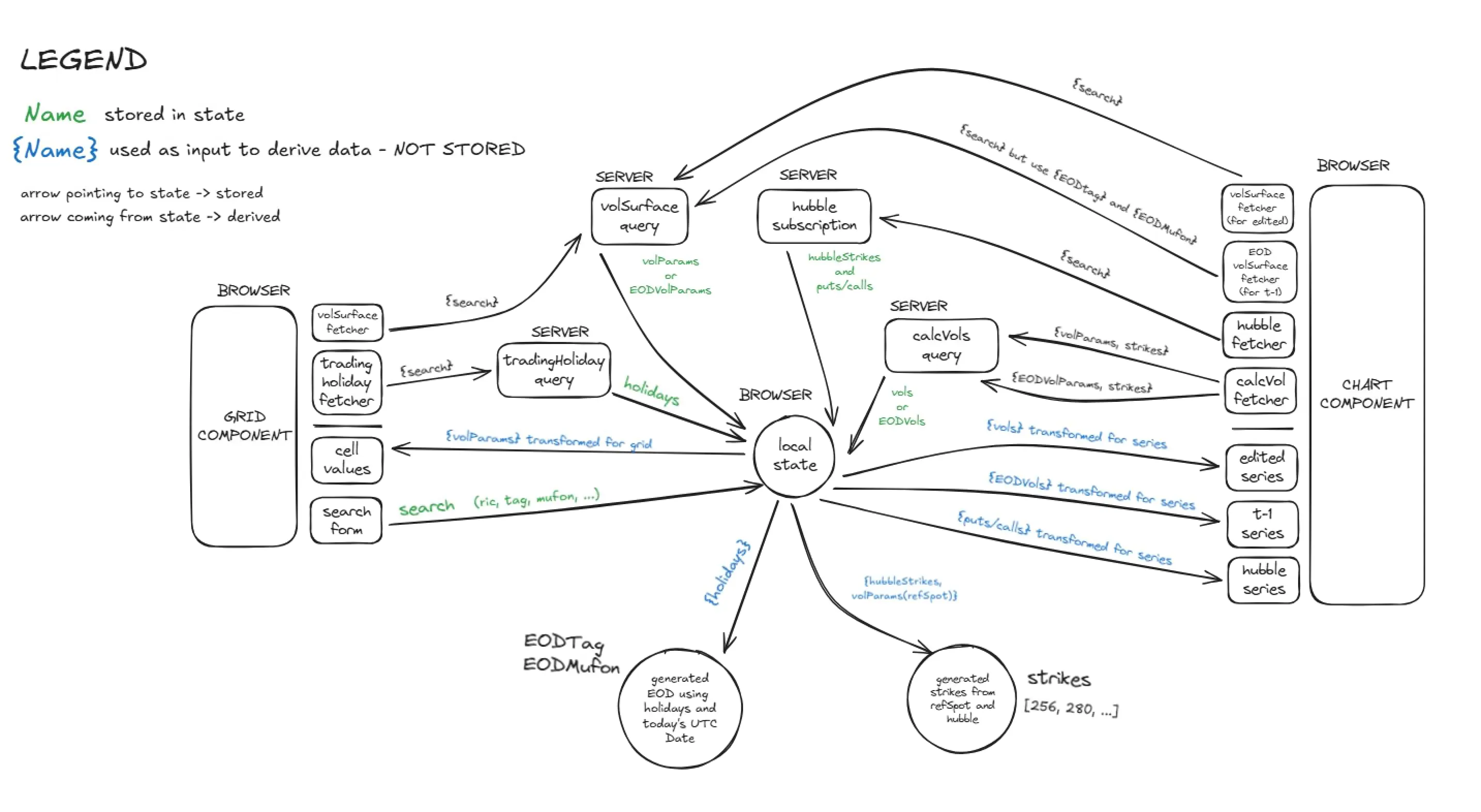
Immediately we started questioning things:
- Why is the UI querying trading holidays just to compute an end of day date?
- Why not have the backend return the right value directly?
These daily brainstorming sessions were essential for us to untangle the mess and identify opportunities to simplify.
Choosing the New Stack
While documenting the old flows, we also kicked off the new project. We did not have total freedom: the new UI had to live in an existing monorepo alongside other applications. In hindsight, this constraint turned out to be a strength. By sharing the same stack, developers across teams could contribute more easily.
Our stack looked like this:
- Monorepo tool: Nx
- State management: Redux Toolkit (RTK) plus RTK Query
- UI components: internal design system for consistency
- Build tool: Vite
- Testing: Vitest for unit tests, Cypress for integration
- Tooling: ESLint, Prettier
- Mocking: Mock Service Worker, to decouple frontend development from backend availability
- Widgeting: Dockview, a zero dependency docking library with an intuitive API
My guiding principle was simplicity. I wanted us to rebuild a complex system in a way that even a junior developer could understand.
Another core principle we adopted was having one single source of truth for our types. Initially, we generated them from our mocks, and later from an OpenAPI contract supplied by the backend. This approach gave us incredible confidence. If a query parameter changed in the API contract, we would get an instant build time error somewhere in our code. The full codebase’s type system was derived directly from the specs, which completely eliminated a whole class of potential bugs.
Building for Simplicity
We embraced a functional approach with React hooks and leaned heavily on RTK Query for server state management. For real time updates, we combined RTK Query with sockets.
One concern I had was performance. Redux is not always the best fit for fast streaming data, and traders’ sockets could produce thousands of messages per second. Instead of adopting a new state library, we added a tiny client side buffer, just four lines of code. It collected incoming messages in memory and flushed them to Redux four times per second. Profiling showed negligible CPU usage, so this was a solid compromise.
Contrary to the old codebase, we avoided unnecessary complexity like web workers for this. The main thread handled it just fine. Using Mock Service Worker, we stress tested the app with tens of thousands of continuous messages, well beyond realistic scenarios.
The First Release
Our first production release was intentionally minimal: a grid and a chart. These showed the fundamental data traders relied on, volatility surfaces across expiries and volatility smiles at given strikes.
At this stage, we did not involve traders directly in demos. The app was still too rough, and we wanted to polish the basics before showing it. Instead, we kept management engaged with weekly demos. Once the backbone was stable, we could make reliable estimates for adding further widgets.
A complex highlight for us was orchestrating socket connections, two separate services, and funneling the data into grid and chart widgets. Once we solved that, the rest of the UI was much more approachable.
This might get a bit technical, so feel free to skip the following part, but we found a very elegant approach to managing the socket messages using RTK Query’s onCacheEntryAdded lifecycle hook. The concept looks something like this:
export const helloApi = createApi({
// ...
endpoints: (build) => ({
helloSubscription: build.query({
// ...
async onCacheEntryAdded(
arg: { name: string },
{ updateCachedData, cacheDataLoaded, cacheEntryRemoved }
) {
// 1. Initiating web socket
const ws = new WebSocket('socket-url')
try {
await cacheDataLoaded
// 2. Registering listener
const listener = (event: MessageEvent) => {
const data = JSON.parse(event.data)
updateCachedData((draft) => {
draft.push(data)
})
}
ws.addEventListener('message', listener)
await cacheEntryRemoved
ws.close()
} catch {
// error handling
}
}
})
})
})Now, of course, our final implementation was a bit different. We needed our socket instance to be global since we never wanted to close it, and we had to support more message types. So we used a tiny abstraction to manage listeners in an in-memory data structure.
But the idea is very similar. The beauty of this function is that the subscription lifecycle is managed in one place. The await cacheDataLoaded and await cacheEntryRemoved pause the execution perfectly, allowing us to have an easy-to-read, linear model without jumping around.
The Data Flow
The new flow we designed was simple and declarative:
- User inputs values.
- Values are stored in redux.
- A redux subscription reads those values.
- They trigger RTK Query requests or subscriptions.
- Returned data is optionally transformed.
- Components consume the hook directly, grids with AG Grid, charts with Highcharts.
Orchestrating the grid and chart components was not a trivial task either. The grid revolved around a single, centralized place to run all pre and post data updates, a design similar to what is described in this article. For the charts, we relied directly on the Highcharts API to set and update the data, which was crucial for performance as it allowed us to avoid destroying and recreating the series on each re-render.
For cascading queries, we used the RTK Query skip option to delay execution until conditions were met. This removed the need for brittle, imperative orchestration.
Collaboration with the Backend
Our daily standups with the backend team were critical. API contracts required constant discussion and iteration. Some endpoints had to be redesigned multiple times as we tried to strike the right balance between backend efficiency and frontend usability.
That open communication was what kept us moving. Even when we felt stuck in the early days, trying to grasp obscure legacy logic, our close collaboration and steady domain learning helped us untangle one knot at a time.
Lessons Learned
Domain knowledge takes time. I learned there are no shortcuts. The reason we succeeded was partly technical but mostly organizational:
- We were a small team, able to share ideas quickly.
- We communicated openly and consistently, both internally and with stakeholders.
- We focused on simplicity and clarity in the new codebase, ensuring that future developers would never feel as stuck as we did with the legacy one.
Conclusion
I have since left the project, but I hear it continues to grow and gain momentum. Traders now use a modern UI that feels faster, simpler, and more reliable than the legacy version.
Looking back, the hardest part was at the very beginning: dissecting the old code and building confidence in my own understanding. Once our foundation was set, everything else flowed more smoothly.
I am proud to have left behind software that is readable, modern, and valuable, a solid base for future teams to build on.